
Data Management Best Practices
Journée IID des professionnels et professionnelles de recherche affiliés à l’Université Laval sur la gestion et l’usage des données de recherche
November 26, 2024




Research assistant at Takuvik (Laval University)
Remote sensing, modeling, data science, data visualization, programming
https://github.com/PMassicotte
philippe.massicotte@takuvik.ulaval.ca
@philmassicotte
https://fosstodon.org/@philmassicotte
www.pmassicotte.com
Old-school computing in laboratories
Laboratory computer programs often use proprietary file formats.
This likely means that:
You are forced to buy a license which can be expensive.
You depend on the commitment of the company to support the file format in the future.

When you depend on profit companies
At the Bodega Marine Laboratory at the University of California, Davis, some computers still run on Microsoft Windows XP (released in 2001), because of the need to maintain compatibility with a scanning laser confocal microscope and other imaging equipment, says lab director Gary Cherr.
To work with current Windows versions, the team would have to replace the whole microscope. The marginal potential gains aren’t yet worth the US$400,000 expense, Cherr reasons.

Examples of CSV and TSV files

This dataset contains 4 variables (columns). The first line generally includes the names of the variables.
A comma-separated values file (.csv).

A tabs separated values file (.tsv).

The GeoJSON format

Data: https://bit.ly/2pAjOAr
The GeoTIFF format
Often associated with satellite imagery.
GeoTIFF is a public domain metadata standard that allows georeferencing information to be embedded within a TIFF file. The potential additional information includes map projection, coordinate systems, ellipsoids, datums, and everything else necessary to establish the exact spatial reference for the file.

The GeoTIFF format (SST)
A GeoTIFF can contain information such as the Sea Surface Temperature (SST).

The GeoTIFF format (SST)
A closer look allows us to better visualize the values (i.e., water temperature) within each pixel.

File naming: who can relate?

File naming basic rules
For sequential numbering, use leading zeros to ensure files sort properly.
- For example, use
0001,0002,1001instead of1,2,1001.

When file naming goes wrong!

The glitch caused results of a common chemistry computation to vary depending on the operating system used, causing discrepancies among Mac, Windows, and Linux systems.
…the glitch, had to do with how different operating systems sort files.
When file naming goes wrong!
Data files were sorted differently depending on the operating system where the Python scripts were executed.

Working with data from other people

Preserve information: keep your raw data raw
If a script changes the content of a raw data file and saves it in the same file, likely, the script will not work the second time because the structure of the file has changed.

Project directory structure

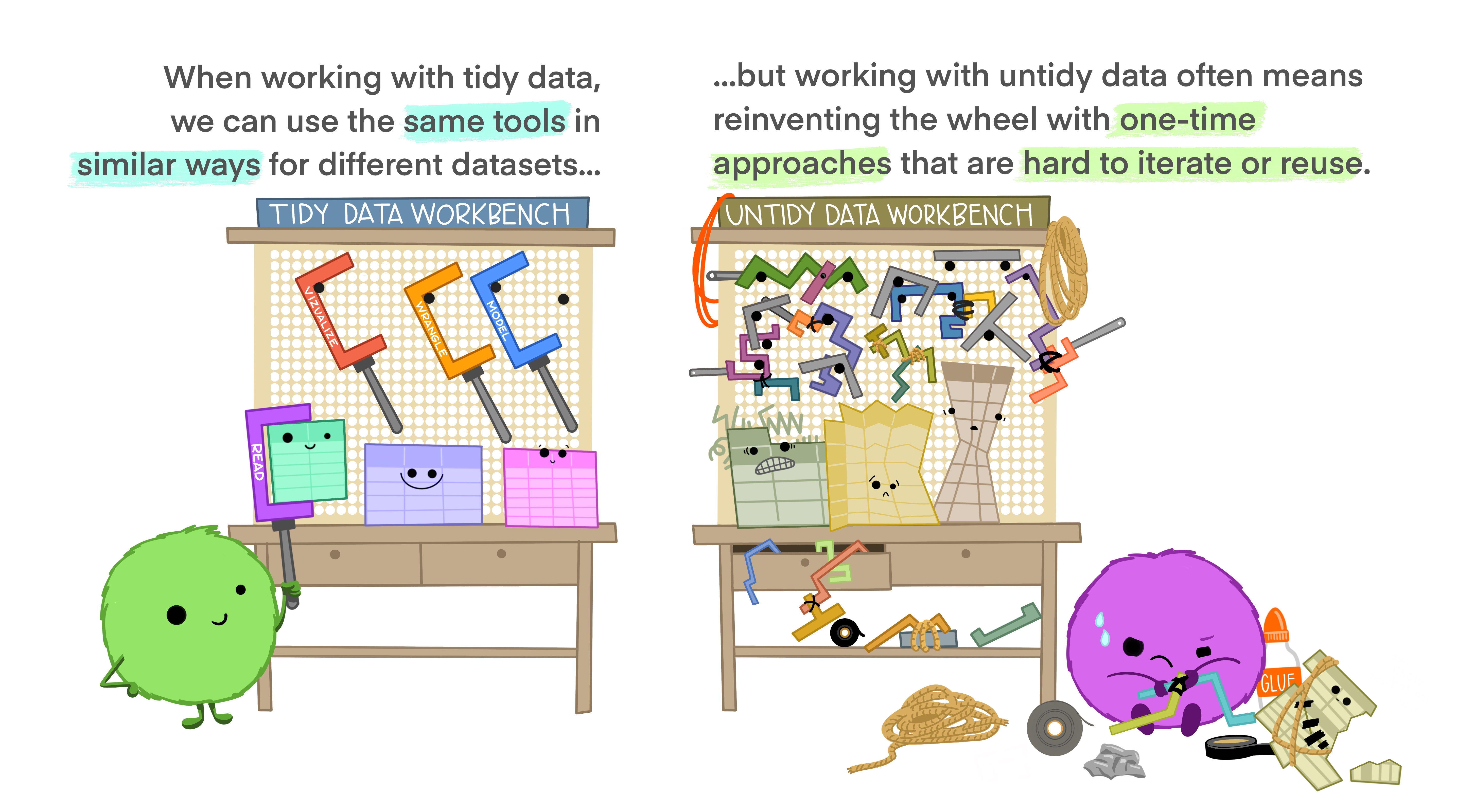
Tidy data

Why do we want tidy data?
Often said that 80% of the data analysis is dedicated to cleaning and data preparation!
Well-formatted data allows for quicker visualization, modeling, manipulation and archiving.
Tidy data
The main idea is that data should be organized in columns with each column representing only a single type of data (character, numerical, date, etc.).

How data is often structured
Many researchers structure their data in such a way that it is easily manipulated by a human, but not so much programatically.
A common problem is that the columns represent values, not variable names.
Example: a datasheet with species abundance data.

How data should be structured
After proper transformations, the data is now tidy (or in normal form). Each column is a variable, and each row is an observation.

Keep your data as rectangle tables
If you use a spreadsheet program, keep your data arranged as rectangular tables. Otherwise, it makes data importation difficult.

Keep your data as rectangle tables
These two examples show the same data. One is arranged as two tables whereas the other is correctly formatted into a single rectangle table.
This sheet has two tables

This sheet has one table

Keep your data as rectangle tables
Do not be that person 😩😖😠😤😣🤦♀️🤦♂️😑😓

Variable names

Variable names
Do not use special characters or spaces (same as for file names).

Visualization
In this example, we see that there is an outlier in the data. Measuring device fault? Manual entry error?

It is not if, but when your hard drive will fail.

Restoring from an incremental backup

Publishing your data
The traditional way to publish data is to include it as supplementary information with your paper.
- In an appendix along with your paper (assuming that your paper is published in an open-access journal).
- Data presented in an appendix are rarely reviewed by peers.
The Directory of Open Access Journals is useful for searching for open access journals.
Public announcement
Summary tables in a PDF article are not very useful!

You should rather provide the data in a way that is easily importable into a programming language as supplementary information (for example, a CSV file).
What is a data paper?
A data paper is similar to a traditional scientific paper.

What is a data paper?
The data associated with the paper is available online with an associated DOI.

